Subscribe to my newsletter
What this post is about
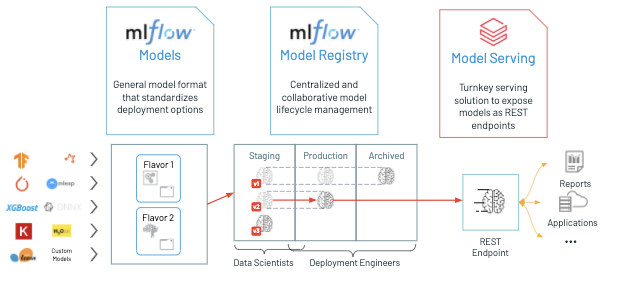
How to use custom transformers extended from sklearn, and publish those as API using databricks model serving by wrapping them inside mlflow.
extending sklearn BaseEstimator, TransformerMixin
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score
import mlflow
import mlflow.sklearn
from mlflow.models.signature import infer_signature
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
URL = 'https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data'
df = pd.read_csv(URL, header=None, names=['age','sex','cp','trestbps','chol','fbs','restecg','thalach','exang','oldpeak','slope','ca','thal','num'])
df['target']=np.where(df['num'] > 0,1,0)
df.head()
age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal num target
0 63.0 1.0 1.0 145.0 233.0 1.0 2.0 150.0 0.0 2.3 3.0 0.0 6.0 0 0
1 67.0 1.0 4.0 160.0 286.0 0.0 2.0 108.0 1.0 1.5 2.0 3.0 3.0 2 1
2 67.0 1.0 4.0 120.0 229.0 0.0 2.0 129.0 1.0 2.6 2.0 2.0 7.0 1 1
3 37.0 1.0 3.0 130.0 250.0 0.0 0.0 187.0 0.0 3.5 3.0 0.0 3.0 0 0
4 41.0 0.0 2.0 130.0 204.0 0.0 2.0 172.0 0.0 1.4 1.0 0.0 3.0 0 0
import random
from sklearn.base import BaseEstimator, TransformerMixin
#Custom Transformer Class
class NewFeatureTransformer(BaseEstimator, TransformerMixin):
def fit(self, x, y=None):
return self
def transform(self, x):
x['flag'] = np.random.choice([0,1,2,3], size= len(x))
self.x = x
return self.x
train, test = train_test_split(df, test_size=0.2)
train, val = train_test_split(train, test_size=0.2)
print(len(train), 'Train Examples')
print(len(val), 'Validation Examples')
print(len(test), 'Test Examples')
new_features_input = df.columns
new_transformer = Pipeline(steps=[('new', NewFeatureTransformer())])
preprocessor = ColumnTransformer(transformers=[('new', new_transformer, new_features_input)])
# Now join together the preprocessing with the classifier.
clf = Pipeline(steps=[('preprocessor', preprocessor)], verbose=True)
#fit the pipeline
clf.fit(df)
#create predictions for validation data
#y_pred = clf.predict(val)
output = clf.transform(df)
output = pd.DataFrame(data=output, columns=[i for i in df.columns]+['flag'])
output.head()
age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal num target flag
0 63 1 1 145 233 1 2 150 0 2.3 3 0.0 6.0 0 0 3
1 67 1 4 160 286 0 2 108 1 1.5 2 3.0 3.0 2 1 3
2 67 1 4 120 229 0 2 129 1 2.6 2 2.0 7.0 1 1 3
3 37 1 3 130 250 0 0 187 0 3.5 3 0.0 3.0 0 0 0
4 41 0 2 130 204 0 2 172 0 1.4 1 0.0 3.0 0 0 2
class ModelOut(mlflow.pyfunc.PythonModel):
def __init__(self, model):
self.model = model
def predict(self, context, model_input):
results = self.model.transform(model_input)
results = pd.DataFrame(data=results, columns=[i for i in df.columns]+['flag'])
return results
custom conda env
mlflow_conda={'channels': ['defaults'],
'name':'conda',
'dependencies': [ 'python=3.7', 'pip',
{'pip':['mlflow','scikit-learn','cloudpickle','pandas','numpy']}]}
mlwflow setup and infer signature
with mlflow.start_run(run_name='custom_pythonmodel_run'):
#log metrics
# log model
signature = infer_signature(df, output)
# log model
mlflow.pyfunc.log_model(artifact_path="custom_pythonmodel",
python_model=ModelOut(model=clf),
signature=signature,
#code_path=['/dbfs/custom_class.py'], #if we had saved our custom transformer class as a .py file on dbfs
conda_env=mlflow_conda
)
#print out the active run ID
run = mlflow.active_run()
print("Active run_id: {}".format(run.info.run_id))
run_id = mlflow.search_runs(filter_string='tags.mlflow.runName = "custom_pythonmodel_run"').iloc[0].run_id
run_id
model_name = "custom_pythonmodel"
model_version = mlflow.register_model(f"runs:/{run_id}/custom_pythonmodel", model_name)
#output
Registered model 'custom_pythonmodel' already exists. Creating a new version of this model...
Created version '2' of model 'custom_pythonmodel'.
from mlflow.tracking import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=model_version.version,
stage="Production",
)
#output
'''
Out[29]: <ModelVersion: creation_timestamp=1622096902481, current_stage='Production', description='', last_updated_timestamp=1622096906725, name='custom_pythonmodel', run_id='2d5e6baf945c43ac953d190a0c83871e', run_link='', source='dbfs:/databricks/mlflow-tracking/1455268150401917/2d5e6baf945c43ac953d190a0c83871e/artifacts/custom_pythonmodel', status='READY', status_message='', tags={}, user_id='5139002757734351', version='2'>
'''
mlflow.pyfunc and spark_udf exchange
loaded_model = mlflow.pyfunc.load_model(f"models:/{model_name}/production")
predict = loaded_model.predict(df)
loaded_model = mlflow.pyfunc.spark_udf(f"models:/{model_name}/production")
predict = loaded_model.predict(sparkdf)
payload format before and after api call
#API call
import os
os.environ["DATABRICKS_TOKEN"] = "## databricks token here ##"
import os
import requests
import numpy as np
import pandas as pd
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(dataset):
url = 'https://adb-3647786.10.azuredatabricks.net/model/custom_pythonmodel/2/invocations'
headers = {'Authorization': f'Bearer {os.environ.get("DATABRICKS_TOKEN")}'}
data_json = dataset.to_dict(orient='split') if isinstance(dataset, pd.DataFrame) else create_tf_serving_json(dataset)
response = requests.request(method='POST', headers=headers, url=url, json=data_json)
if response.status_code != 200:
raise Exception(f'Request failed with status {response.status_code}, {response.text}')
return response.json()
score_model(df)
#output return payload
'''
[{'age': 63.0,
'sex': 1.0,
'cp': 1.0,
'trestbps': 145.0,
'chol': 233.0,
'fbs': 1.0,
'restecg': 2.0,
'thalach': 150.0,
'exang': 0.0,
'oldpeak': 2.3,
'slope': 3.0,
'ca': '0.0',
'thal': '6.0',
'num': 0,
'target': 0,
'flag': 1},
{'age': 67.0,
'sex': 1.0,
'cp': 4.0,
'trestbps': 160.0,
'chol': 286.0,
'fbs': 0.0,
'restecg': 2.0,
'thalach': 108.0,
'exang': 1.0,
'oldpeak': 1.5,
'slope': 2.0,
'ca': '3.0',
'thal': '3.0',
'num': 2,
'target': 1,
'flag': 3},
{'age': 67.0,
'sex': 1.0,
'cp': 4.0,
'trestbps': 120.0,
'chol': 229.0,
'fbs': 0.0,
'restecg': 2.0,
'thalach': 129.0,
'exang': 1.0,
'oldpeak': 2.6,
'slope': 2.0,
'ca': '2.0',
'thal': '7.0',
'num': 1,
'target': 1,
'flag': 1}]
'''